

米Intelは7月26日(日本時間で7月27日朝6時)、Intel Acceleratedと呼ばれるオンラインイベントを開催、同社のプロセスおよびパッケージング技術についての最新情報を説明した。
プロセス ノードの命名ルールをIntel 7~18Aへ再編
まず同社はProcess Nodeに関する新しいNaming Ruleを説明した。もともとProcess Nodeの数字は、ここ10年ほど実際の数字とかなりかけ離れたものになっているのはご存じの通り。おまけに(これはIntelだけではないが)細かい改良を積み上げたものを違うプロセスノード(例えばTSMCなら16FF/12FFとか)で表現しているから判り難い。
-

Photo01: 10nm SuperFinプロセスを10nmと表現することにしたのはいいのだが、ではIce Lake世代の10nmプロセスは? Legacy 10nmとかなんだろうか?
このあたりもあるのと、さらに将来のロードマップを考えてIntelはNaming Ruleを一新した(Photo01)。さて、これの内容であるが
- Intel 7: 旧10nm Enhanced SuperFin。10nmと比較して、同じ消費電力で10~15%動作周波数を引き上げられる(Photo02)。このIntel 7を利用するのはまずClientのAlder Lakeで、これが2021年内。そしてSapphire Rapidsが2022年第1四半期に生産開始となることが明らかにされた(Photo03)。
- Intel 4: 旧7nm。2023年前半中に量産開始予定である(Photo04)。このIntel 4で初めてEUVが利用されることになる。このIntel 4は、クライアント向けのMeteor Lakeと、サーバー向けのGranite Rapidsの量産に利用される。またこのEUV向けのマスク製造装置であるが、IMS Nanofabricationが提供することが明らかになった(Photo05)。
-

Photo02: 基本10nmの延長にあるので、エリアサイズそのものは変わらないようで、なのでトランジスタ数そのものはこの世代では増やせない(というか、増やすとそのままダイサイズが増える)。
-
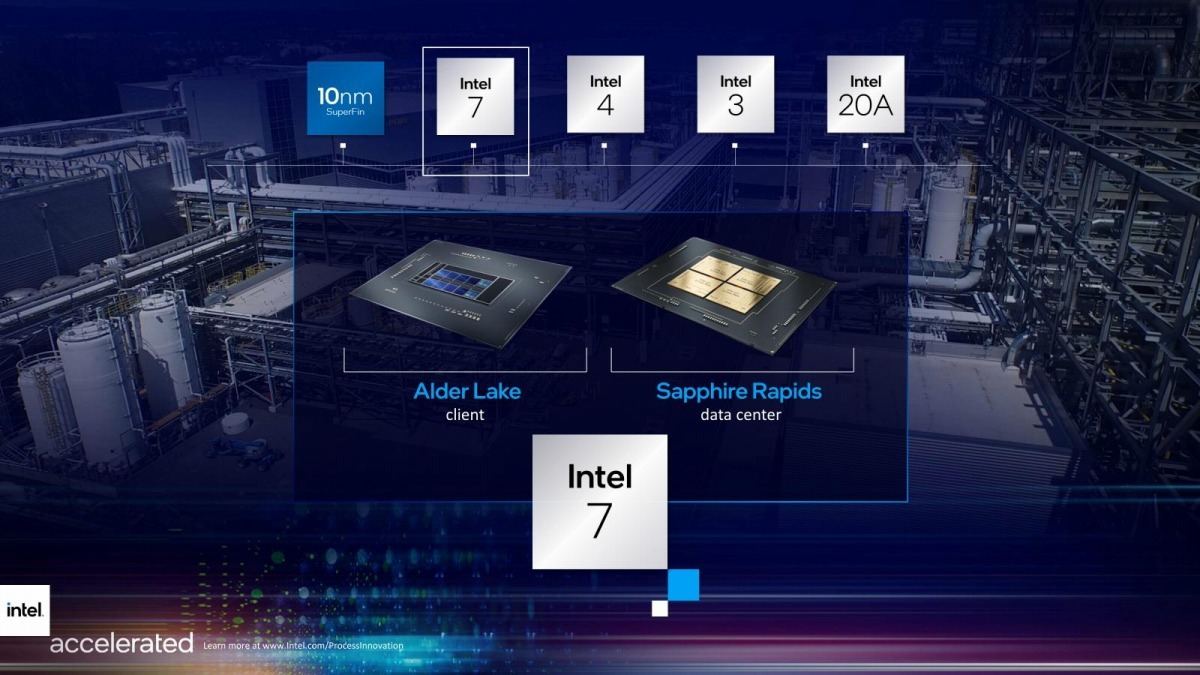
Photo03: ここで明確にSapphire RapidsのDelayが確認された形になる。
-

Photo04: このMeteor Lakeは2022年第1四半期にTape inするという話であった。つまりそのころにこの4nmのPDKが提供開始になるという話であろう。
-

Photo05: マスク製造装置としては大手であるIMS Nanofabricationが供給するのは理には適っているのだが、TSMC/Samsung/etc…がEUVのステッパの奪い合いをしている関係で、マスク製造装置も奪い合いになっている感があり、その意味では「よく確保できたな」という感じではあるのだが。
ちなみにEUVに関して言えば、High NAのEUV装置の導入も予定しており、2025年以降に利用を開始する(Photo06)という話が出てくる。プロセスとしては後述のIntel 18A世代であろうか。ステッパはASMLが2024年までに開発を終える予定のEXE:5000を予定しているように見える(Photo07)。もっとも、EXE:5000が納入されたからと言って、すぐにHigh NAでバリバリ生産が出来るという訳でもなく、しばらくは利用者側での調整とか検証が入るだろうから、2025年中に量産に入れるかどうかはちょっと微妙なところに見える。
- Intel 3: 旧7nm++。High Performance Libraryとか、increased intrinsic drive currentというあたり、基本のトランジスタ構造そのものは変更がなく、ただしセルライブラリの変更とか配線構造の最適化、EUVの利用の拡大(つまり回路層とM0/M1以外にもEUVを適用する)、などが並んでいるあたりは、基本的にはIntel 4の延長にあるものと解される(Photo08)。このIntel 3は2023年後半に利用可能となる予定だ。
- Intel 20A: 旧5nm。最大の特徴はRibbonFETとPowerViaである(Photo09)。RibbonFETはGAA(Gate All Around)構成の一種である。GAAは既にいくつか記事があるが、例えばこちらなど分かりやすい。この記事ではimecが2018年にIEDMで発表したナノワイヤとナノシートを利用したGAA構成を紹介しているが、IntelのRibbonFETはナノシートを積層する方法で、しかもimecに比べると横に広く、その分薄い構成になっている。Intelによればこの方式だと、駆動電流を増すためにはnanoribbonを上に積層すれば済むので、FinFETの時と異なり面積が増えない(FinFETではFinを増やすとその分面積も増える)のがメリットとしている。
-

Photo06: まぁそもそもEUVのステッパーを提供しているのがASMLしかない状態だから、High NAのステッパーも当然ASMLの提供になる。
-
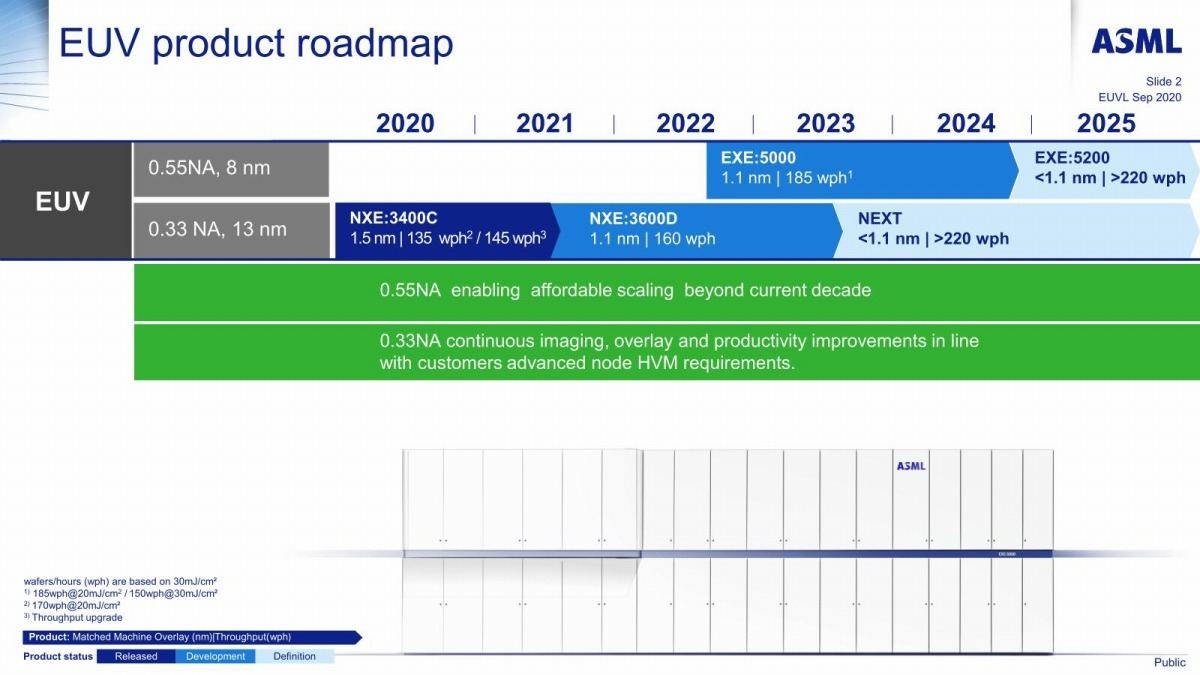
Photo07: ASMLが今年1月に示したロードマップより。以前は0.33NAの先に0.55NAの製品が来るので、NXE:Nextが0.55NA対応という話であったが、今は0.55NAは別シリーズ製品に切り替わった模様。2024年中に開発を終わらせて製品リリースを予定しており、これが出てくるタイミングでHigh NAに切り替えてゆきたいのだろうが。
-
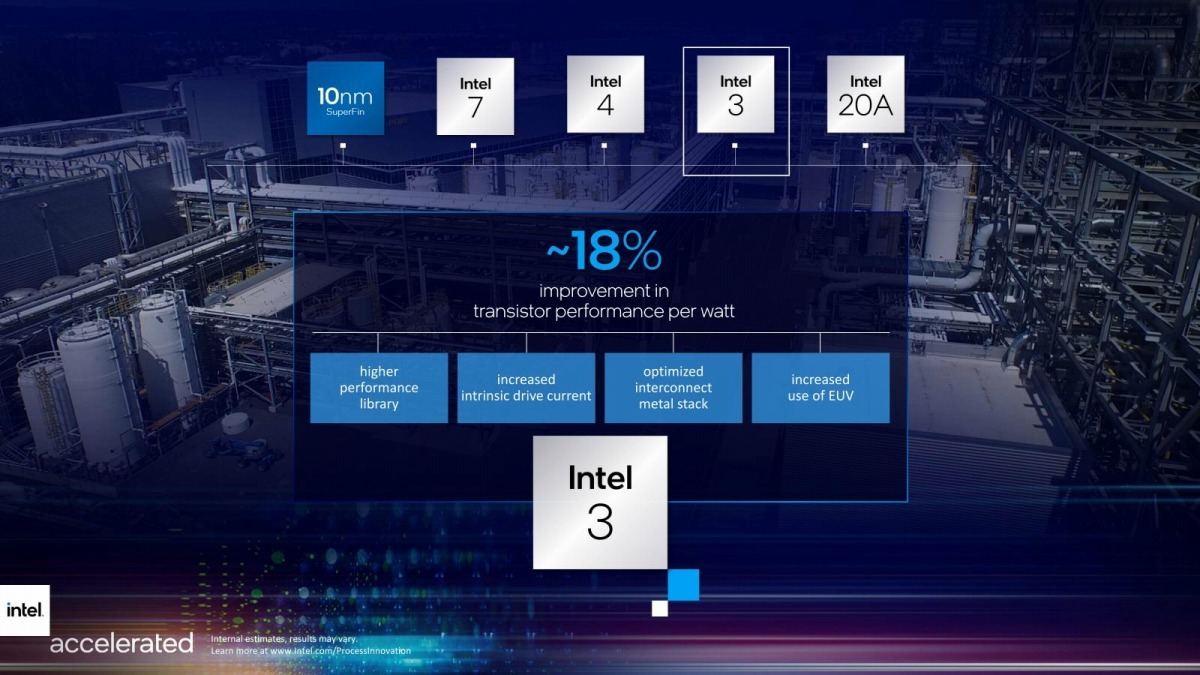
Photo08: もともとこれは7nm++だから、そう大きな変更は行われないだろうとは想定されていた。
-

Photo09: Namingの理由は、この世代あたりからオングストロームレベルにに突入することを明確に示したということだそうだ。実際次は18Aになるわけで、これは従来なら1.8nmと表現していたものだ。オングストロームはSI単位系に含まれていないので、数値としてこれを使うのは違反だが、まぁプロセスの名称だから構わないという事だろう。
-

Photo10: SamsungのMBCFET(Multi-Bridge-Channel FET)に近い感じではあるが、まぁTSMCも含めてどこもGAAの第1世代はナノシートを使う模様なので、その意味では割とコンサバティブというべきか。
もう一つの特徴であるPowerViaであるが、従来だと配線と電源供給を回路層の上に順に積み重ねていた。これに対しPowerVIAでは、配線層は従来通り回路層の上に積層するが、電源層は回路層の下に積層する形になる(Photo11)。このIntel 20Aは2024年前半に利用可能となり、量産に入る見込みである。
-

Photo11: なんとなくこのPowerViaの目的は、後述するFoveros Omni/Directに向けた配慮ではないかという気がする。
- Intel 18A: 旧5nm++。現在はまだ技術開発フェーズであり、2025年の利用開始を目指している(Photo12)。
-

Photo12: とはいえ元は5nm++だから、5nm(つまりIntel 20A)のマイナーバージョンアップな気もする。
改めて時間軸で整理すると
2021年 :10nm(量産中)
2021年後半:Intel 7
2023年前半:Intel 4
2023年後半:Intel 3
2024年前半:Intel 20A
2025年 :Intel 18A
となる形だ。
パッケージング技術のアップデート
これに合わせてパッケージングについてもアップデートが紹介された。まずEMIB。要するにIntel独自の2.5Dパッケージだが、現行の55micron間隔のBumpを、次世代では45micron、その次には40micronまで縮小するとしている(Photo13)。これより小さい間隔についてはFoverosで対応という話で、Intel 4で製造されるMeteor LakeはFoverosを利用することも明らかにされた(Photo14)。またPonte VecchioはEMIB+第2世代Foverosを利用して製造されることも明らかにされた(Photo15)。
-

Photo13: よりBall pitchを詰めることで、多数の配線を通せるようになる。Intelは引き続きPackage OptionとしてEMIBを広く利用してゆくつもりであり、競合技術であるTSMCのCoWoSの中でもCoWoS-Rだと配線ピッチを4micronまで詰められることを考えると、まだ追いついているとは言い難いものの、それなりに競争力を増すための努力は欠かせないだろう。
-

Photo14: ついでにMeteor LakeがChiplet構成になることもここから明らかにされた事になる。
-

Photo15: 第1世代はLakefieldに使われたもので、Alder Lakeもこの第1世代のままと思われる。Meteor Lakeが第2世代の最初のクライアント向け製品となるが、時期的にはPonte Vecchioが先になる「筈」。
これに続くものとして、Foveros OmniとFoveros Directも発表された(Photo16)。まずFoveros Omni、かつてはOmni-Directional Interconnectと呼ばれていた技術であるが、これはおそらく先のPowerViaを前提にした技術である。Photo17にクロスセクションの図が出ているが、base dieとtop dieは向かい合わせになっており、間にInterposerが挟まる格好である。第1世代のFoverosは、base dieとtop dieのどちらもbumpは下向きになっていた。なので、base dieのbumpからでる信号をTSV経由でtop dieまでroutingする方式になっていた。この方式だと3層以上のdie stackingが可能であり、実際Lake fieldではDRAM・Compute(CPU+GPU+Memory I/F)・PCHという3つのDieを積層していた。これに対しFoveros Omniではdieの配線面を向かい合わせにしているので、原則として2層までの積層しかできないが、その分TSVは最小になる(電源とか、パッケージの外に引っ張り出す信号はTSV経由でパッケージ底面に引っ張り出さないといけない)し、より高密度に実装ができる。
-

Photo16: Foveros Omni/Directはどちらも2023年から利用可能になる、としている。
-
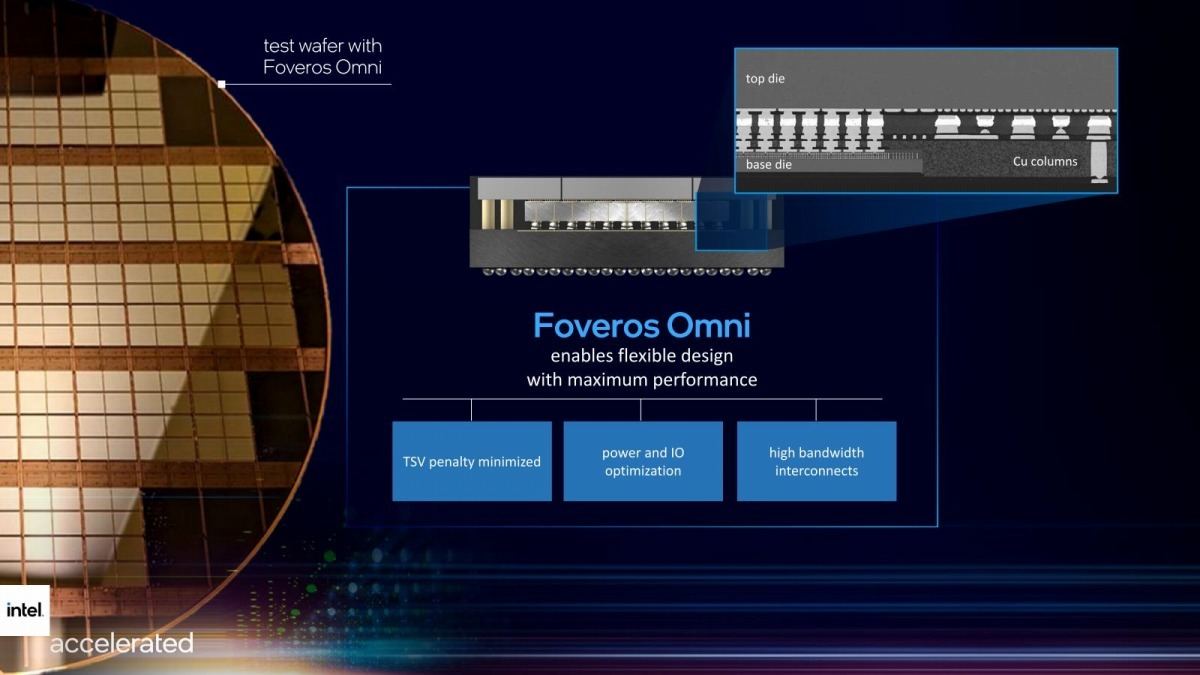
Photo17: もちろん原理的にはTSVを使って、この上にさらに積層することも不可能ではないが、TSVを使った接続は猛烈にLatencyが出そうである。
これをもっと進めたのがFoveros Directで、もうInterposerすら挟まずに2つのチップを直接貼り合わせる技法である(Photo18)。こちらはBump Pitchは10micronまで短縮され、1平方mmあたり10000個の接続が可能になるというものだ。熱的な問題を気にしなければ、この方式は非常に効率が良いだろう。それこそAMDがこの前発表した3D V-Cacheに近いことを、TSV無しで実現することも不可能ではない。
-
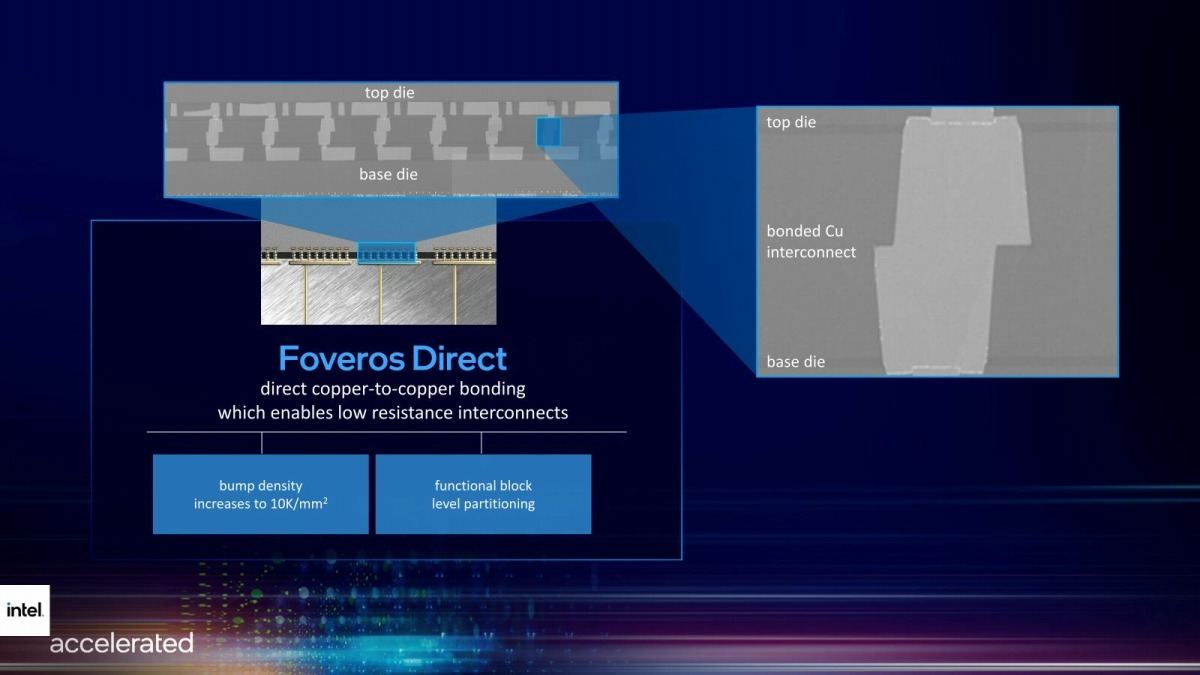
Photo18: これ、TSMCがSoICで説明したF2F(Face to Face)Optionそのまんま、という気はしなくもない。TSMCはこの張り合わせにSoIC Bondなる謎の超技術を使うとしているが、Intelはどうするつもりなのだろう?
ただこのFace-to-Faceの接続はそれ故に色々問題もある(特に電源pinのroutingとか)わけで、この辺りをスムーズに解決できるめどが立っているかどうかを含めて、どこまで実用性があるのか正直良く判らないというのが筆者の現時点での感想である。
半導体製造サービスの最初の顧客はAmazonとQualcomm
最後に、AmazonがIntel Foundry Service(IFS)のPackaging(Photo19)を、QualcommがIntel 20A(Photo20)をそれぞれ使うことが発表された。
-

Photo19: Amazonは子会社のAnnapurna Labsが開発しているNeoverseベースのSoCの後工程にIntelのEMIBなのかFoverosなのか不明だが、どちらかを使うという事だと思う。
-

Photo20: QualcommはもともとTSMCとSamsungを使い分けというか両方使っているベンダーであり、ここにIntelも加わった、ということだろう。
なお2025年以降に向けてもよりGAAのStackingを増してゆくとか、次世代のPowerVia、さらにSilicon PhotonicsをベースにしたOptical Packageの開発を推進してゆくなど、意欲的なロードマップを提示し、2025年には再びProcess Performanceでリーダーシップを取るポジションに復帰するとした。ちなみに今回紹介された技術のより詳細については、10月27・28日にサンフランシスコで開催されるIntel innovationで公開される予定とのことだ。
-

Photo21: 率直な感想:「まだSilicon Photonics諦めてなかったのか」。